R 语言主成分分析(PCA)实战教程 |
您所在的位置:网站首页 › simca pca怎么显示名称 › R 语言主成分分析(PCA)实战教程 |
R 语言主成分分析(PCA)实战教程
|
作者:落痕的寒假原文:https://blog.csdn.net/LuohenYJ/article/details/97950522 声明:本文章经原作者同意后授权转载。 主成分分析 Principal Component Methods(PCA)允许我们总结和可视化包含由多个相互关联的定量变量描述的个体/观察的数据集中的信息。每个变量都可以视为不同的维度。如果数据集中包含 3 个以上的变量,那么可视化多维超空间可能非常困难。 主成分分析用于从多变量数据表中提取重要信息,并将此信息表示为一组称为主成分的新变量。这些新变量对应于原件的线性组合。主成分的数量小于或等于原始变量的数量。PCA 的目标是识别数据变化最大的方向(或主成分)。换句话说,PCA 将多变量数据的维度降低到两个或三个主要成分,这些成分可以图形化可视化,同时信息损失最小。PCA 属于机器学习降维方法质之一,但是仅仅对线性数据有用,非线性数据建议使用 TSNE。 本文描述了 PCA 的基本概念,并演示了如何使用 R 软件计算和可视化 PCA。此外,我们将展示如何揭示解释数据集变化的最重要变量。主要内容如下: 基础 计算 实例 总结 1. 基础 1.1 基础概念了解 PCA 的细节需要线性代数的知识。在这里,我们将仅通过简单的数据图形表示来解释基础知识。 在下图 1A 中,数据在 XY 坐标系中表示。通过识别数据变化的主要方向(称为主成分)来实现降维。PCA 假设方差最大的方向是最 “重要的”(即最主要的方向)。 在下图 1A 中,PC1 轴是样本显示最大变化的第一个主方向。PC2 轴是第二个最重要的方向,它与 PC1 轴正交。通过将每个样本投影到第一个主成分上,我们的二维数据的维数可以减少到一个维度(图 1B)。 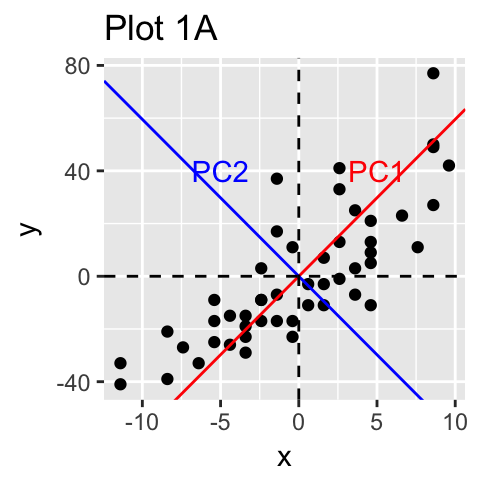
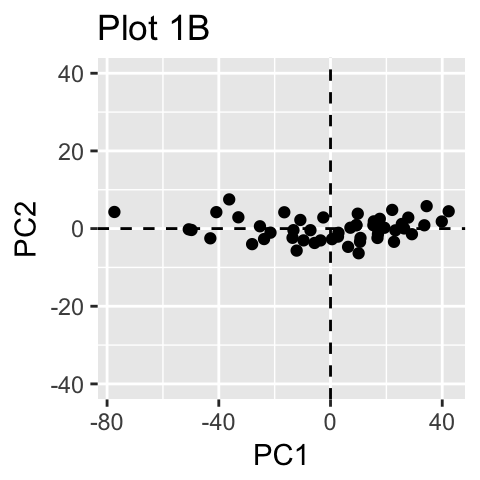 从技术上讲,每个主成分保留的方差量是通过所谓的特征值来测量的。请注意,当数据集中的变量高度相关时,PCA 方法特别有用。相关性表明数据存在冗余。由于这种冗余,PCA 可用于将原始变量减少为较少数量的新变量(= 主成分),解释原始变量的大部分方差。
从技术上讲,每个主成分保留的方差量是通过所谓的特征值来测量的。请注意,当数据集中的变量高度相关时,PCA 方法特别有用。相关性表明数据存在冗余。由于这种冗余,PCA 可用于将原始变量减少为较少数量的新变量(= 主成分),解释原始变量的大部分方差。
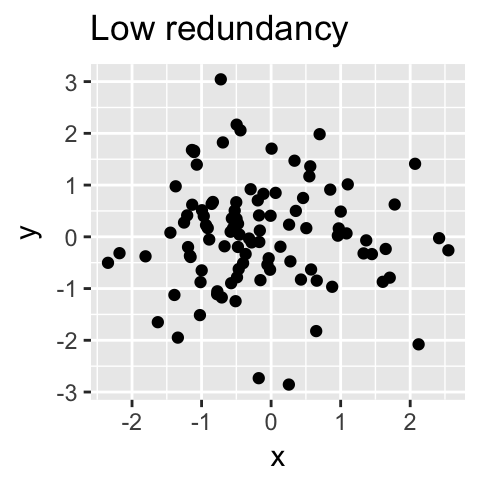
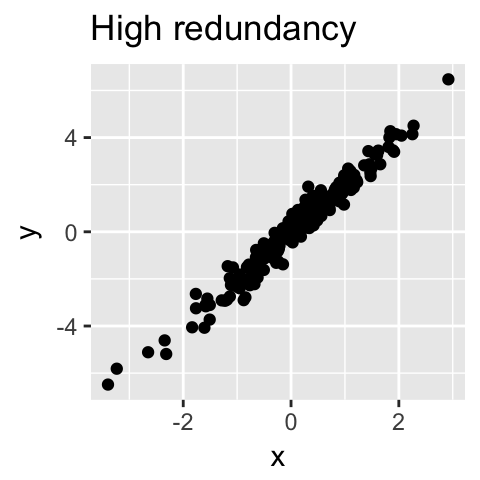 总的来说,主成分分析的主要目的是:
总的来说,主成分分析的主要目的是:
识别数据集中的隐藏模式; 通过消除数据中的噪声和冗余来降低数据的维度; 识别相关变量。 1.2 计算过程目前很多书籍讲PCA并不那么通俗易懂。PCA 是用来降低数据维度的,维度降低后的主成分和原来的变量不是一个东西。如果想获得原来数据中重要的变量,删除无关变量,请参考特征工程。PCA 计算过程很简单,具体如下: 1.2.1 数据处理假设我们有这样的 2 维数据: 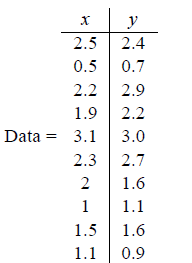 其中行代表了样例,列代表特征,这里有 10 个样例可以认为有 10 辆汽车,x 是千米/小时的速度,y 是英里/小时的速度。
其中行代表了样例,列代表特征,这里有 10 个样例可以认为有 10 辆汽车,x 是千米/小时的速度,y 是英里/小时的速度。
通常 x,y 都是不同的变量,如果要放到一起来比较,一般都要进行数据标准化使得各个变量数据能够放到一块比较。这里简单一点,只减去平均值。分别求 x 和 y 的平均值,然后对于所有的样例,都减去对应的均值。这里 x 的均值是 1.81,y 的均值是 1.91,那么一个样例减去均值后即为(0.69, 0.49),得到: 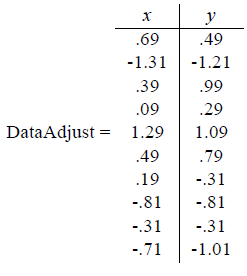 1.2.2 计算特征值
1.2.2 计算特征值
在现实情况下,我们需要通过计算数值矩阵的相关系数矩阵或者协方差矩阵来求得特征值和特征向量,进而获得主要成分。相关系数矩阵和协方差矩阵能够变量间相关性,主成分分析会删除和其他变量相关性强的变量,留下更具有代表性的变量。相关系数矩阵相当于消除量纲的表示变量间相关性的一个矩阵,协方差系数矩阵是没有消除量纲的表示变量间相关性的矩阵。相关系数矩阵是协方差系数矩阵的特例,通常在 PCA 中,如果数据量很少用相关系数矩阵,很多用协方差系数矩阵。 这里主要计算协方差系数矩阵,因为协方差系数更具有实际代表意义。主要计算过程网上都有。那么我们能够获得矩阵的特征值和特征向量(这部分是线性代数的内容)。如下所示: 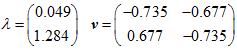
这里特征值 0.049 对应特征向量为:  特征值 1.284 对应特征向量为:
特征值 1.284 对应特征向量为:

主成分分析降维的意思就是根据特征值的大小挑选主成分变量,比如这里我们要把二维数据降为一维,就选取最大特征值 1.284 对应的特征向量计算主成分得分。计算公式如下: 
PC1 就是我们说的主成分得分,特征向量 (-0.677, -0.735) 就是我们说得主成分系数。我们所获得降维后的一维变量就是通过这个公式对每行数据通过上面公式获得的。结果如下: 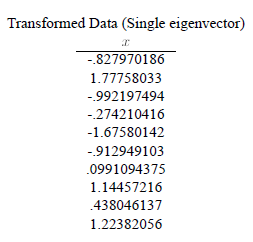 1.2.3 可视化描述
1.2.3 可视化描述
上述过程可以简单用图来描述,我们有一个经过归一化的数据,这个数据各个样本点都是分散的,无规律的。 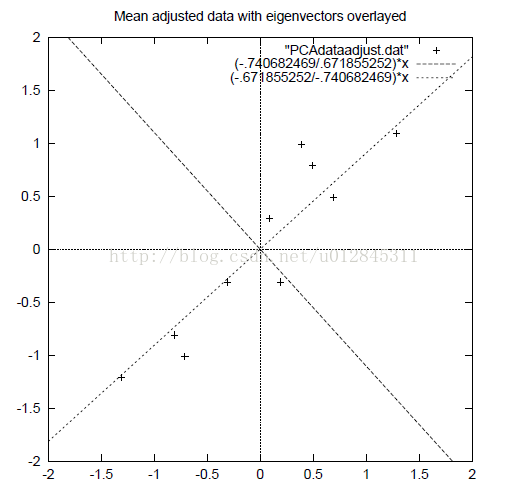
如果我们将原数据降为二维(这里实际维度没有变化,一维不好表示)。那么结果如下: 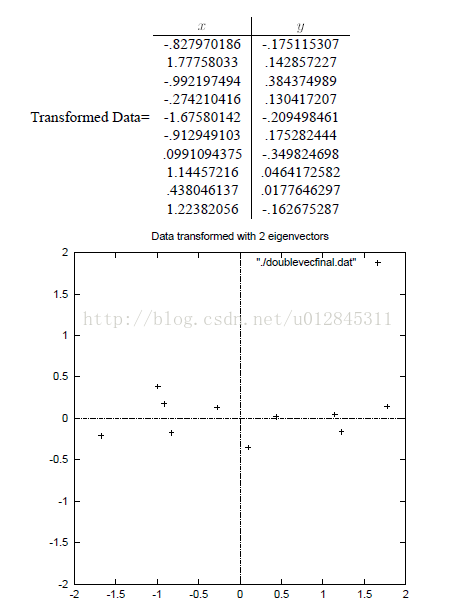 可以看到现在各个样本点分布像一条直线,与 x 轴平行。样本点的 x 坐标就是第一主成分,第二主成分就是 y 坐标。
可以看到现在各个样本点分布像一条直线,与 x 轴平行。样本点的 x 坐标就是第一主成分,第二主成分就是 y 坐标。
其中贡献率是表示投影后信息的保留程度的变量,计算公式就是前 K 个特征值除以总的特征值之和。计算公公式如下: 
比如本文例子有两个特征值 1.284 和 0.049,如果我们降为一维主成分,那么第一主成分贡献率为 1.284/( 1.284 + 0.049 ) = 0.963 。 PCA详细原理说明见:《[机器学习] PCA (主成分分析)详解》。 2. 计算 2.1 R 包用于计算 PCA 的 R 软件中提供了来自不同软件包的多个函数: prcomp()和princomp()[内置] PCA( [FactoMineR包] dudi.pca()[ade4包] epPCA()[ExPosition包] 无论您决定使用什么功能,您都可以使用factoextraR包中提供的 R 功能轻松提取和可视化 PCA 的结果。 通过install.packages("FactoMineR", "factoextra")安装所使用的包。 # 调用 R 包library("FactoMineR")library("factoextra")Warning message:"package 'FactoMineR' was built under R version 3.6.1"Loading required package: ggplot2Welcome! Related Books: `Practical Guide To Cluster Analysis in R` at https://goo.gl/13EFCZ我们将使用来自factoextra包的decathlon2演示数据集,数据集如下: data(decathlon2)head(decathlon2) 但我们只选择部分数据进行计算,处理如下:
decathlon2.active
但我们只选择部分数据进行计算,处理如下:
decathlon2.active |
【本文地址】
今日新闻 |
推荐新闻 |